| d-view wrote: |
| Конвертеры MS (плагин Office 1.1) перегоняют только в RTF или могут и в TXT? |
| Quote: |
| Xpdf 3.01 pl2 - утилита командной строки, конвертер PDF-файлов. Файлы настроек для конвертации файлов с русским языком включены. Бесплатно. 1,67 Мб. 08.02.2006. http://www.foolabs.com/xpdf/home.html |
| Quote: |
| Converters pack for PDF-Filter plugin 1.1 - несколько фильтров-конвертеров с настройками для плагина (PDF)Filter: DjVu, DMP (Windows minidump), ExeDLL, Inx (Installshield decompiler), Java, PDF, PS. Freeware. 4,2 Мб. Автор: Vladimir L. Olovyannikov. 01.06.2006. http://wincmd.ru/plugring/pdf_filter_converters_pack.html |
| Quote: |
|
GetText is a free file-to-text conversion command-line utility which extracts textual contents from files of multiple formats. To perform text conversion, GetText uses Text Filters (read more about Text Filters). Kryloff Technologies, Inc. supplies this utility with the following filters: * Htm2Txt.dll which converts HTM and HTML files into TXT files; * Rtf2Txt.dll for RTF convertion (Rich Text Format files); * Pdf2Txt.dll for PDF convertion (Adobe Portable Document Format files); * Wpd2Txt.dll for WPD convertion (Word Perfect files). * Hlp2Txt.dll which converts MS Help (.HLP) files into TXT files; * DocDll.dll for DOC convertion (MS Word files); the filter is designed to function under MS Windows 2000, XP, 2003, Vista and later; * XLSDll.dll for XLS convertion (MS Excel files); functions under MS Windows 2000, XP, 2003, Vista and later; * PPTDll.dll for PPT convertion (MS Power Point files); functions under MS Windows 2000, XP, 2003, Vista and later; * Uncd2Txt.dll to extract plain text from UNICODE files. * XMLDll.dll to extract plain text from or convert XML file contents into an appropriate code page. |
| Quote: |
| --Конвертер PDF->TXT из плагина (PDF)filter 1.05.51 |
| Quote: |
| -Конвертеры MS (плагин Office 1.1) перегоняют только в RTF |
| Quote: |
| --Сразу ламерский вопрос:
Нельзя ли этот плагин присобачить для сравнения файлов одинакового содержания, но разных форматов. Допустим, скачал я из Сети файлы - текстовый, гипертекст, Wоrd, ООо |
| Quote: |
| --Converters pack for PDF-Filter plugin 1.1 - несколько фильтров-конвертеров с настройками для плагина (PDF)Filter: DjVu, DMP (Windows minidump), ExeDLL |
| Quote: |
| --Если не устраивает IFilter, то есть еще такая приблуда:
GetText |
| Alextp wrote: |
| там самих конвертеров нет |
| Alextp wrote: | ||
IMHO нельзя. У Тотала нет таких средств. Тут где-то тема была |
| Alextp wrote: | ||
|
| Stepan_Lameroff wrote: |
| Если не устраивает IFilter, то есть еще такая приблуда: GetText |
| Quote: |
| Как я понял, он использует KT Text Filters (библиотеки) - а они платные... |
| Quote: |
| Нельзя ли этот плагин присобачить для сравнения файлов одинакового содержания, но разных форматов. |
| Alextp wrote: | ||
Жалко. Там для DOC конвертер. |
| Lev wrote: |
| Посмотрите в сторону CompareIt - шароварный компаратор... |
| Quote: |
| Format_TXT=C:\Program Files\totalcmd\plugins\wlx\PDFFilter\PDF\xpdf\pdftotext.exe %fp%-f %p1% %lp%-l %p2% -layout %fn% %o% %hide%
Format_TXT=C:\Program Files\totalcmd\plugins\wlx\PDFFilter\PDF\xpdf\pdftotext.exe %fp%-f %p1% %lp%-l %p2% -enc KOI8-R -layout %fn% %o% %hide% pdftotextKOI |
| Quote: |
| Версия с XPDF, по-моему, не ищет в PDF, т.к., ИМХО:
1) Нужно на той же странице скачать и положить в каталог файлы раскладки для кириллицы; 2) Нужно взять настройки из прилагающегося к ним файла, указать в них пути к (1) и внести всё это в файл настроек XPDF |
| Quote: |
|
GetFileContentsFromIFilter function - This function reads the contents of files using the indexing service's filter implementation. The indexing service is installed on Windows 2000/XP machines (and NT machines running the Option Pack). This function lets you read the contents of a variety of files recognized by the indexing service without knowing the internal file format. An ActiveX DLL implemeting this function is also available here. |
| Ник wrote: |
| 4) FB2:
Для этого формата есть FB2 to Any (Дмитрий Грибов) http://www.gribuser.ru/xml/fictionbook/ , но я не понял, как его запустить в командной строке - написал автору, жду ответа... |
| Моторокер wrote: |
| Элементарно грохнуть все тэги, ещё и HTML будет переводить в текст |
| Quote: |
| --По ссылке по поводу IFilter с RSDN пример имеет проблемы с русской кодировкой. Дорабатывать напильником не хотелось (да и CPP подзабыл уже ). Набросал быстро на шарпе - все работает нормально (включая кодировки), только проблема с PDF - стоит Acrobat 8.1 Но думаю сегодня доделать. Если интересно - могу выложить. |
| Quote: |
| --И еще просьба.
Нельзя ли сделать в конфиге секцию (или ключ) с обработчиком по умолчанию? |
| Alextp wrote: |
| По поводу FB2: нужна утилита, которая стрипает теги |
| Ник wrote: | ||
Это да - но, кроме тэгов, там есть и встроенные бинарные объекты - например, картинки - как их стрипать? |
| Alextp wrote: |
| нужна утилита, которая стрипает теги. Чтобц можно было запускать так:
tags in_file out_file |
| Alextp wrote: |
| Хорошо. Надо тоько чтобы тескт разделялся пробелами после стрипанья тегов. |
| Моторокер wrote: | ||
Что это значит? |
| Моторокер wrote: |
| тупо читаю всю строку, удаляю бинарики, заменяю <p> на #13#10, удаляю тэги, сохраняю строку |
| Quote: |
| Что это значит?
Значит - чтобы слова не слипались после удаления тэгов... |
| Ник wrote: |
| Прости, но он ресурсов жрёт по ощущениям - больше, чем FB2 to Any - раз в десять!!! |
| Ник wrote: |
| Давайте уж договоримся, что все тексты нужно временно (пока Гислер не сделает полноценную поддержку УНикода) сводить в Windows-1251. |
| Ник wrote: |
| для поисковика сделать лог-файл + показывать предупреждения, что типа это не та кодировка - не могу найти - и в конце работы писать список файлов не с той кодировкой |
| Моторокер wrote: |
| Работает хоть быстрее? |
| Моторокер wrote: |
| как он узнает, что кодировка та? |
| Quote: |
| файлы, начинающиеся с последовательности байт $FE$FF или $FF$FE, всегда интерпретируются как тексты в UTF-16, с $EF$BB$BF - как тексты в UTF-8 |
| Ник wrote: |
| описание View64 |
| Quote: |
| --SilverCoders DocToText - говорит, не может конвертировать. Может, какие проблемы с именами?
Руками попробовал - он из файла делает UTF-8 и что с этим делать? |
| Quote: |
| Или нужно делать многократный поиск: по Windows-1251, по ASCII, по KOI-8R, по UTF-8, UTF-16... |
| Quote: |
| Кстати, Алексей, а нельзя ли для поисковика сделать лог-файл + показывать предупреждения, что типа это не та кодировка - не могу найти - и в конце работы писать список файлов не с той кодировкой? |
| Alextp wrote: |
| Еще какие-нибудь нужно? {RTF}? {UTF16}? |
| Alextp wrote: |
| Что писать в лог-файл? Строку запуска конвертера? Успешно ли сконвертировалось? можно. Еще что-то? |
| Alextp wrote: |
| Кстати, если сделать ключ {RTF}, то конвертеры для RTF не будут нужны... |
| Stepan_Lameroff wrote: |
| GetTextIFilter...
... Для работы требуется .Net Framework 2.0+ |
| Quote: |
| Что такое в данном контексте RTF, мне не ясно - а вот последнее, думаю, пригодится.
Нужно - ИМХО - обязательно ASCII (866) и KOI-8R. |
| Quote: |
| Ну типа какая кодировка была - т.е. какую плагин "выявил" (если это реально), а юзер уже сравнит с тем, что есть на самом деле... |
| Quote: |
| Вот это не очень ясно - плагин сам сконвертирует? |
| Quote: |
| А как тогда, если кодировка внутри RTF неправильно задана? |
| Quote: |
| Тестирую - вроде всё ОК, но для RTF я из осторожности использую GetText, а не встроенную возможность. |
| Quote: |
| Единственное замечание - если не получается конвертировать файл в текст (например, PDF без текстового слоя вообще), то выскакивает соответствуюшее сообщение и требует нажать "ОК". При этом, как я понимаю, работа поиска останавливается. |
| Quote: |
| ИМХО, лучше было бы в самом конце поиска давать сообщение (не блокирующее ТК!!): "не смогло конвертировать столько-то файлов" |
| Stepan_Lameroff wrote: |
| FiltDump... |
| Quote: |
| Ищем через GetText слово "не" - найдено 37 файлов из 41. Не найденные 4 штуки - в 3-х нет слова "не"
Ищем через встроенный в плагин конвертор RTF по тому же слову - найдено 26 файлов из 41... |
| Alextp wrote: |
| Вот если научиться распознавать кодировку RTF |
| Stepan_Lameroff wrote: |
| FiltDump от Microsoft (лежала приблуда в Platform SDK Передается имя файла, результат выводит в stdout. Работает кривовато (имеется в виду качество извлечения текста), но быстро. |
| funduk wrote: |
| я так понял, что в документах, содержащих гиперссылки, оные в текст не переводятся, а просто игнорируются. А есть такие утилиты, которые не игнорируют их? |
| Quote: |
| добавлены кодировки UTF16, UTF16LE, UTF16BE |
| Athari wrote: |
| Не думаешь добавить полноценную поддержку всех кодировок, которые держит Винда? |
| Quote: |
| FB2=wscript.exe /B /NoLogo "c:\Program Files\FB2 to Any\fb2txt_commandline.vbs" "{In}" "{Out}" {CP:UTF8} |
| Ник wrote: |
| И вот ещё - есть какой-то странный
DjVu IFilter http://www.lizardtech.com/download/dl_download.php?detail=doc_ifilter&platform=win но я так и не смог с ним разобраться и понять - зачем он нужен... |
| Quote: |
| Windows Script Host
Script: c:\Program Files\FB2 to Any\fb2txt_commandline.vbs Line: 90 Char: 1 Error: The stylesheet does not contain a document element. The stylesheet may be empty, or it may not be a well-formed XML document Code: 80004005 Source: FB2_to_TXT.FB2TXTExport |
| Alextp wrote: |
| использовать через GetTextIFilter |
| Ник wrote: |
|
Спасибо, но он на .NET - я такой софт принципиально не использую - после того, как выкачал пачку обновлений безопасности для него чуть ли не больше его самого... Пусть Билл Г. свой отстой пользует... |
| Alextp wrote: |
| Может ему каталог (текущий) надо задавать? |
| Quote: |
| FB2Any 0.2 - конвертор из формата FB2 в текст, гипертекст, RTF и прочее. Бесплатно. Автор: Дмитрий Грибов. 2,9 Мб. 19.04.2006. http://www.gribuser.ru/xml/fictionbook/ |
| Quote: |
| MsXML.dll Microsoft Data Access Components 8.0.6730.0
MSXML3.dll Microsoft(R) MSXML 3.0 SP 7 8.70.1113.0 MSXML3A.dll Microsoft Data Access Components 8.20.8730.1 MSXML3R.dll Microsoft Data Access Components 8.20.8730.1 MSXML4.dll Microsoft(R) MSXML 4.0 SP 2 4.20.9841.0 MSXML4R.dll Microsoft(R) MSXML 4.0 SP1 4.10.9404.0 MSXMLR.dll Microsoft Data Access Components 8.0.6730.0 |
| Quote: |
| Msxml2.FreeThreadedDOMDocument.4.0 |
| Quote: |
| У меня показывает ошибку - может какие библиотеки нужны или Винды старые - у меня Windows 2000 SP4 ?
У меня следующие файлы есть в System32: |
| Quote: |
| Кстати, WDX Guide - это твой? |
| Alextp wrote: |
| Если не хватает библиотек, то и из комстроки конвертер у тебя запускаться не будет.
Наверное писать надо Грибову. |
| Lev wrote: |
| Еще тогда кодировку {All} = ищутся все известные плагину кодировки |
| Ник wrote: |
| ИМХО, это нужно именно самому ТК - галки выбора кодировки ставить. |
| Quote: |
| Для плагина, как мне кажется, это нужно только, если файлы могут быть в разных кодировках - и если ТК не поддерживает мультикодировочный поиск в этих типах файлов. |
| Quote: |
| Кстати, а куда делась кодировка KOI8-R (у меня часто письма хранятся именно в ней)? |
| Code: |
|
| Alextp wrote: |
| как будет делаться поиск: плагин конвертит текст, пишет его в разных кодировках в строки. Теперь если есть неск. кодировок, он слепляет строки через #13#10. И ТК находит в одной из код-к.
Или не находит. |
| Quote: |
| То есть, поиск замедлится в несколько раз? |
| Quote: |
| Нельзя ли как-то автоопределение кодировок поставить |
| Quote: |
| ISO это сила! |
| Quote: |
| А ведь для кириллицы есть ещё пара десятков кодировок разных... |
| Alextp wrote: |
| Ты их используешь? |
| Quote: |
| [off]Имхо лицензии даются по количеству голов программиста а не по кол-ву прог. Для получения очередной лицензии придётся выдать себя за другого человкека и писать плаги от его лица[/off] |
| D1P wrote: |
| Гислер даст. Давно хочу попробовать получить дополнительно пару-другую лицензий, но всё никак не решу, кому их дарить |
| Lev wrote: |
| Где-то в форуме, кто-то писал, что никак не может получить лицензии на остальные плагины, после первого. |
| Quote: |
| .rtf Rich text
.docx Microsoft WORD 2007 (OOXML) .xlsx Microsoft Excel 2007 (OOXML) .pptx Microsoft PowerPoint 2007 (OOXML) .doc Microsoft WORD ver5.0/95/97/2000/XP/2003 .xls Microsoft Excel ver5.0/95/97/2000/XP/2003 .ppt Microsoft PowerPoint 97/2000/XP/2003 .sxw/.sxc/.sxi/.sxd OpenOffice.org .odt/.ods/.odp/.odg Open Document .jaw/jtw Ichitaro ver5 .jbw/juw Ichitaro ver6 .jfw/jvw Ichitaro ver7 .jtd/jtt Ichitaro ver8/9/10/11/12 .oas/oa2/oa3 OASYS/Win .bun New pine/pine 5/pine 6 .wj2/wj3/wk3/wk4/123 Lotus 123 .wri Windows3.1 Write .pdf Adobe PDF .mht Web archive .html HTML .eml The export type of OutlookExpress |
| Quote: |
| ; xdoc2txt
XDOC=%COMSPEC% /CCONV\XDOC\XDOC2TXT.EXE "{In}">"{Out}" sxw=XDOC sxc=XDOC sxi=XDOC sxd=XDOC odt=XDOC ods=XDOC odp=XDOC odg=XDOC docx=XDOC docm=XDOC xlsx=XDOC xlsm=XDOC pptx=XDOC pptm=XDOC doc=XDOC xls=XDOC ppt=XDOC rtf=XDOC jaw=XDOC jtw=XDOC jbw=XDOC juw=XDOC jfw=XDOC jvw=XDOC jtd=XDOC jtt=XDOC oas=XDOC oa2=XDOC oa3=XDOC bun=XDOC wj2=XDOC wj3=XDOC wk3=XDOC wk4=XDOC 123=XDOC wri=XDOC pdf=XDOC mht=XDOC html=XDOC eml=XDOC |
| Quote: |
| Просьба разработчику подправить Readme.html, |
| antabu wrote: |
| Не работает поиск в некоторых pdf файлах. Помогите, пожалуйста, определить кодировку текстового слоя в файле (после распаковки):
http://www.hij.ru/EV/01_2008.zip |
| Ник wrote: |
| Боюсь, что там в одном и том же файле в текстовом слое текст в нескольких кодировках сразу |
| Quote: |
| XPDF всё равно придётся искать и устанавливать - в Вашем паке его версия более старая, чем та, что уже есть на оф. сайте |
| Ник wrote: |
| и непонятно, зачем держать на диске три копии одной и той же утилиты |
| Quote: |
| Без разницы - сколько качать и сколько потом руками выбрасывать лишнего?
Нет - разница существенная... |
| Quote: |
| Во что Вы собираетесь конвертировать DOC и DOCX и как - в ком.строке или ГУИ?
Скорость для Вас важнее качества? |
| Quote: |
| Какие "варианты формата" Вы имеете ввиду? |
| Alextp wrote: |
| Кто знает как послать в KaspLab? |
| Alextp wrote: |
| Был вирус KLAV-nnnnnn |
| Code: |
CHM=%COMSPEC% /C ..\..\wcx\Total7zip\7zG.exe e "{In}" *.htm* -x!images\ -so > "{Out}" -r {CP:ANSI} {CP:UTF8} |
| Code: |
XDOC=%COMSPEC% /C Conv\XDoc2txt\xdoc2txt.exe "{In}" > "{Out}" |
| Code: |
XDOC=%COMSPEC% /C %COMMANDER_PATH%\Plugins\WDX\TextSearch\Conv\XDoc2txt\xdoc2txt.exe "{In}" > "{Out}" |
| Alextp wrote: |
| у меня плагин не там |
| Quote: |
| rar p c:\path\Arc.rar >c:\temp\txt.txt
|
| Quote: |
| unzip -p c:\path\Arc.zip >c:\temp\txt.txt |
| al000032 wrote: |
| А не знаете каким образом умудряется сам Total искать в архивах? Вроде бы и во временную директорию полностью архив не распаковывается?... |
| al000032 wrote: |
| И еще - не знаете как в стандартом поиске Totala искать текст в файлах сразу и в ANSI и в UTF8, а не по очереди? |
| Dimsok wrote: |
| Годны только проги, которые по умолчанию в txt конвертят? |
| Skif_off wrote: |
| Dimsok
В каких форматах вы хотите искать? |
| Code: |
TOTALCMD#BAR#DATA |
| Code: |
EPUB=ebook-convert.exe "{In}" "{Out}" |
| Dimsok wrote: |
| ток конечно со скоростью у Calibre проблемы. |
| Dimsok wrote: |
| -f "%%#" -e "utf8" -p "%t%%~n#" |
| Code: |
EPUB=путь\balabolka_text.exe -f "{In}" -p "{Out}" |
| Quote: |
| Аналогично:
|
| Quote: |
| А с кодировкой что? С UTF-8 плаг работает? |
| Code: |
Balabolka_text=cmd /c Conv\balabolka_text\balabolka_text.exe -f "{In}" -o > "{Out}" |
| Code: |
Balabolka_text_7z=cmd /c Conv\balabolka_text\7z.exe e "{In}" -so|Conv\balabolka_text\balabolka_text.exe -i -o > "{Out} |
| Skif_off wrote: |
| Mailk
Вы проверяли, плагин работает с xdoc2txt линейки 2.х? |
| Code: |
%COMSPEC% /C Conv\XDoc2txt\xdoc2txt.exe "{In}" > "{Out}" |
| Skif_off wrote: | ||
| Mailk
А в TextSearch.ini строка с xdoc2txt оставлена всё та же
? |
| Dimsok wrote: |
|
cross-plus-a.___/balabolka_text.zip Работает в разы шустрей, правда не столько форматов поддерживает. Поддерживаемые форматы файлов: AZW, AZW3, CHM, DOC, DOCX, EPUB, FB2, HTML, MHT, MOBI, ODT, PDF, PRC, RTF, TXT |
| Code: |
[Converters] |
| Quote: |
| С сайта убрали balabolka_text.exe |
| Dimsok wrote: |
| А это что?
|
| Code: |
Компания Common Craft выбрала видео. И хотя этот способ вполне удовлетво- ряет нас и нашу аудиторию, он лишь один из многих, подходящих для представле- ния объяснений таким образом, чтобы они сумели привлечь внимание. Подобных средств так много, что выбор может показаться тяжелой работой. Следующая глава поможет в выборе способа, соответствующего ограничениям, которые накладывает на вас ваша аудитория, и имеющемуся набору инструментов. |
| Quote: |
| Cannot convert file "path\file.docx" to "C:\TempTextSrch.txt".
Command: "C:\Windows\system32\cmd.exe /C Conv\XDoc2txt\xdoc2txt.exe "path\file.docx" > "C:\TempTextSrch.txt"". |
| Code: |
XDOC=%COMSPEC% /C Conv\XDoc2txt\xdoc2txt.exe "{In}" > "{Out}" |
| Alextp wrote: |
| Может плагин ждет %temp% с слешем |
| Code: |
XPS=%COMSPEC% /C ..\..\wcx\Total7zip\Modules\7z_x86\7zG.exe e "{InShort}" *\*\*\*.fpage -so > "{Out}" -r {CP:UTF8} |


| Quote: |
| Бета 1.6, попробуйте |
| Code: |
|
| Code: |
;XDoc2Txt |
| Code: |
;XDoc2Txt |
| Code: |
"{In}" |
| Code: |
"{InShort}" |
| Code: |
XDOC=%COMSPEC% /C chcp 65001 & Conv\XDoc2Txt\XDoc2Txt.exe "{In}" > "{Out}" |
| Code: |
XDOC=%ComSpec% /u /c Conv\XDoc2Txt\XDoc2Txt.exe -u "{In}" > "{Out}" |
| Code: |
;XDoc2Txt |
| Code: |
;XDoc2Txt |
| Google translate wrote: |
| 2.17 2018/10/16
Fixed an issue where extra descriptors are displayed in RTF after 1.9 (Word 2007) Ruby(??) removal of docx Fixed an issue that ended abnormally for some PDFs |
| Avada wrote: |
| kosla
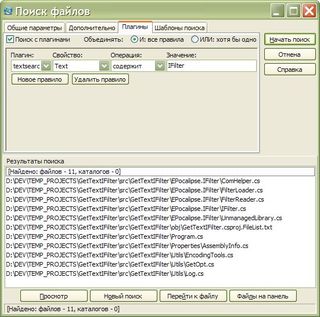
Разумеется, можно. Третья страница диалога поиска TC. Выберите в списке плагин и создайте с ним два правила, объединенные через И. Две разных операции: cодержит и !содержит (то есть не содержит). Для каждой указать нужное значение. |
output generated using printer-friendly topic mod. All times are GMT + 4 Hours